Warped-Compaction: Maximizing GPU Register File Bandwidth Utilization via Operand Compaction
Abstract
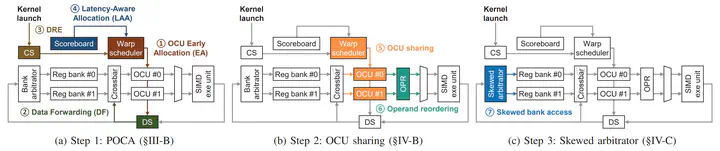
The GPU has been successfully used for diverse emerging compute-intensive applications, including imaging, computer vision, and more recently, deep learning, to name a few. To offer high performance for such applications, it is provisioned with massive Register Files (RFs) to exploit high Thread-Level Parallelism (TLP). As RFs are designed to store thousands of contexts and provide very high bandwidth for uninterrupted supply of operands to hundreds of compute units for high TLP, they have become one of the most power-hungry components in the GPU. Meanwhile, faced with the end of Dennard scaling, it is more important than ever to innovate the microarchitecture of (power-constrained) GPUs to continuously improve the performance of future compute-intensive applications. In this work, we propose a GPU microarchitecture, Warped- Compaction, designed to utilize given RFs more efficiently, instead of relying on larger-capacity and/or higher-bandwidth RFs to further improve GPU performance. Specifically, first, we reverse-engineer the latest GPU’s RF organization through microbenchmarking. This uncovers that each sub-core within a streaming multiprocessor contains only two dual-ported RF banks, and accesses to these banks are arbitrated solely based on register IDs. We also reveal that, despite the modest configurations, RF banks are largely underutilized, staying inactive for 33.5% of the time. Second, we observe that previously proposed RF optimization techniques, data forwarding and dead register elimination, cannot address this underutilization problem. This is mainly due to the (R1) insufficient RF access requests from a limited number of Operand Collector Units (OCUs) and (R2) inefficient operand distribution by the conventional RF bank arbitration. Third, we present two architectural solutions to tackle the observed inefficiency: (S1) OCU sharing and (S2) skewed arbitrator. Building on enhanced OCU early allocation for partially ready instructions and operand forwarding to OCUs, OCU sharing allows two different warp instructions to share a single OCU, and skewed arbitrator evenly distributes register accesses across RF banks, maximizing the utilization of given RF bandwidth. The synergistic integration of these techniques, forming Warped-Compaction, results in 26.1% higher performance and 21.7% better energy efficiency of RF and OCU compared to baseline high-end GPU.
Ipoom Jeong
Assistant Professor
My research interests include CPU/GPU microarchitectures, memory/storage system designs, and smart-I/O devices