Abstract
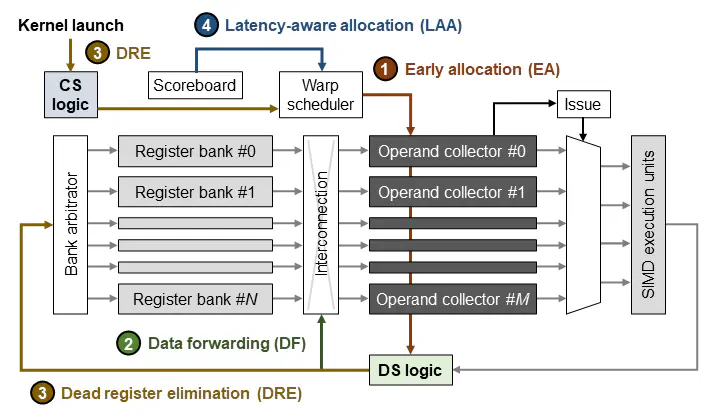
Recent GPUs provisioned with large register files cannot fully utilize the bandwidth between the register files and execution pipelines, as the current policy for allocating operand collectors defers the register file accesses until all the source operands become ready. To tackle this issue, this paper introduces a new operand collector allocation mechanism called Triple-A. Triple-A comprises four key operations. First, Triple-A proactively allocates an operand collector to a warp instruction even if one of its source operands is not yet ready, taking advantage of GPUs’ in-order execution. Second, a computation result can be directly forwarded to an early allocated operand collector along with a data dependence, reducing operand loading time from the register files. Third, Triple-A bypasses register file write operations if the forwarded data is not consumed by any other instruction. Lastly, the early allocation is further enhanced with latency-aware optimization, alleviating the potential performance degradation caused by allocating operand collectors aggressively. Together, these techniques synergistically improve the register bank utilization, demonstrating a 14.1% improvement in performance and an 11.8% reduction in register file energy consumption compared to the state-of-the-art GPUs.
Ipoom Jeong
Assistant Professor
My research interests include CPU/GPU microarchitectures, memory/storage system designs, and smart-I/O devices