Abstract
Out-of-order cores provide high performance at the cost of energy efficiency. Dynamic scheduling is one of the major contributors to this: generating highly optimized issue schedules considering both data dependences and underlying execution resources, but relying heavily on complex wakeup and select operations of an out-of-order issue queue (IQ). For decades, researchers have proposed several complexity-effective dynamic scheduling schemes by leveraging the energy efficiency of an in-order IQ. However, they are either costly or not capable of delivering sufficient performance to substitute for a conventional wide-issue out-of-order IQ.
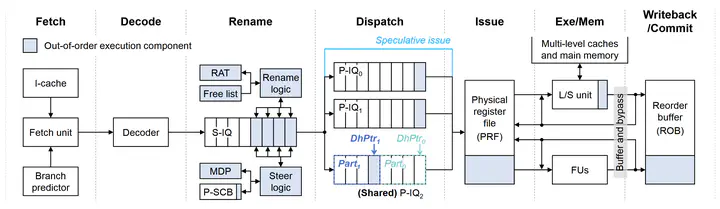
In this work, we revisit two previous designs: one classical dependence-based design and the other state-of-the-art readiness-based design. We observe that they are complementary to each other, and thus their synergistic integration has the potential to be a good alternative to an out-of-order IQ. We first combine these two designs, and further analyze the main architectural bottlenecks that incur the underutilization of aggregate issue capability, thereby limiting the exploitation of instruction-level and memory-level parallelisms: 1) memory dependences not exposed by the register-based dependence analysis and 2) wide and shallow nature of dynamic dependence chains due to the long-latency memory accesses. To this end, we propose Ballerino, a novel microarchitecture that performs balanced and cache-miss-tolerable dynamic scheduling via a complementary combination of cascaded and clustered in-order IQs. Ballerino is built upon three key functionalities: 1) speculatively filtering out ready-at-dispatch instructions, 2) eliminating wasteful wakeup operations via a simple steering technique leveraging the awareness of memory dependences, and 3) reacting to program phase changes by allowing different load-dependent chains to share a single IQ while guaranteeing their out-of-order issue. The net effect is minimal scheduling energy consumption per instruction while providing comparable scheduling performance to a fully out-of-order IQ. In our analysis, Ballerino achieves comparable performance to an 8-wide out-of-order core by using twelve in-order IQs, improving core-wide energy efficiency by 20%.
Ipoom Jeong
Assistant Professor
My research interests include CPU/GPU microarchitectures, memory/storage system designs, and smart-I/O devices